
We are interested in modelling traffic systems. Early traffic systems models were chosen mostly because of their simple properties and were able to give exact, closed form solutions. With the advent of easily available fast computing power, many statistical techniques once considered to be computationally infeasible are now available. With these new techniques, we can now implement more realistic traffic systems models. However even for moderately sized networks, the computation time can still very large and further improvements need to be made so that the implementation is truly feasible. These ideas will be discussed in this talk.

The next section is about Markov assignment models which are a statistical tool for implementing traffic systems models.
After that is on how to efficiently simulate these Markov models.
Finally we have an application of the software MARTS (Markov Assignment for Road Traffic Systems) to the effects of pre-trip information.

In the models we will consider, travellers make informed decisions for today based on previous days's information so we have detailed day-to-day traveller learning. However there is no within-day traveller learning as once traveller has decided on a route, it is not changed according to changing conditions on that day.
We note that here highly-detailed microscopic models (which allow within-day traveller learning) fit the data well as they fit a large number of parameters. However because of this potential for over-parametrisation, they have poor predictive qualities. Since we are mostly concerned with the moderate to long term behaviour of traffic systems, we use mesoscopic models.

Since each traveller has imperfect knowledge of the road network and hence the measured disutilities then each traveller has a perceived disutility which is the measured disutility plus a perceptual random error. This means that each traveller has a different perceived disutility for each route. The basic assumption that we use is that the traveller will then choose the route with the smallest perceived disutility.
For probit route choice, each link (keeping in mind that a route is a sequence of links) has independent Normally distributed perceptual random errors. In this set-up, the exact route choice probabilities are mathematically intractable and so we need to estimate them by simulating Markov assignment models.

A simple example is given on the slide. Suppose that only the previous two days affect today. Then in the example, a traveller gives most weight to what happened yesterday (i.e. 80 %) and only 20% weight to what happened on the day before yesterday.

For each day and each traveller
- Generate random errors for each link on the network
- Apply a shortest path algorithm to find the route with the smallest perceived disutility. We use a label-correcting method as this is the most efficient.
- This route is then assigned to the traveller.
As you can see, this is extremely computationally intensive as there can be thousands of travellers on a network with hundreds of links, all occurring over hundreds of days.


If we run simulations with a high proportion of habitual travellers, we replicate observed traveller behaviour as it is usually the case that many travellers choose the same route everyday, despite changing conditions. If we run simulations with a high proportion of selective travellers then the network flows oscillate in an unrealistic manner. So by replicating realistic behaviour it is extremely fortunate that we also reduce the running time of our simulations.

An example of implicit assignment is given on the slide. Suppose we have 500 travellers for a particular OD pair. We can assign routes to the first 200 travellers explicitly. From these 200 routes, we can then estimate the route choice probabilities which we then use to randomly assign routes according to a multinomial model with these estimated route choice probabilities to the remaining 300 travellers.

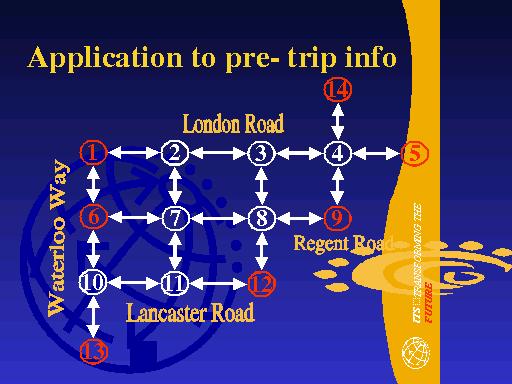
We now look at an application of the software to the effects of pre-trip information. The road network that we use is from the UK city of Leicester, in central England. Throughout the simulations, we examine how travellers react to the quality of the pre-trip information. This is controlled by the variance of the perceptual random error.
(Show slide.)
Here is a diagram of the network. London Road is a major arterial road that runs south-east to north-west, from node 5 to node 1. There are 14 nodes and 18 links. The main origin and destination nodes are nodes 1, 5, 6, 12, 13 and 14 (which are in red) with approximately 3800 travellers on this network, during a 1 hour period.

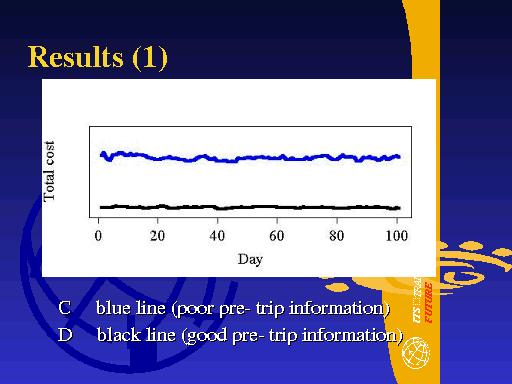

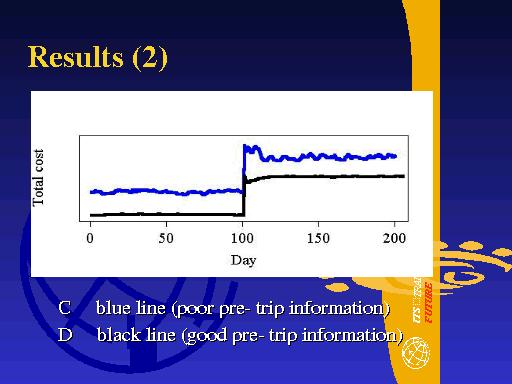
Another important feature in these time series is that scenario D settles down to its new equilibrium faster than scenario C. Again this is because travellers under scenario D have better pre-trip information and so adjust faster to the changed road conditions.

Thank you.